Pipeline
A idéia do pipeline é bem simples.
imagine que você tenha de levar 4 sacas de roupa na lavanderia, lavar, secar e passar cada uma delas.
Você chega à lavanderia às 18 horas e começa o trabalho da seguinte forma:
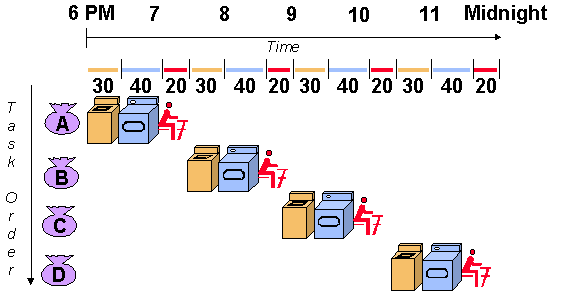
De acordo com o desenho, vc leva 30 minutos lavando a roupa, 40 secando e 20 passando cada saco com uma certa quantidade de roupas.
Se pararmos para analizar este tempo poderia ser otimizado. Da seguinte forma:
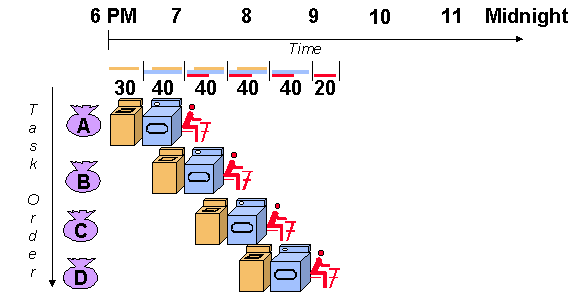
Agora, enquanto um saco está lavando você pode secar o anterior. E como a roupa não depende de que você fique ao lado da máquina, você pode passar a leva anterior e assim otimiza o tempo.
O pipeline funciona assim. Enquanto uma instrução passa para a próxima fase, podemos otimizar o tempo pegando a próxima a ser executada.
Seria ótimo se fosse apenas isto, mas não podemos esquecer que em programas de computador temos instruções condicionais e estas podem gerar erros no pipeline, se não tratadas de maneira correta.
Vamos explicar de maneira mais técnica agora...
O Pipeline é constituído por uma seqüência de estágios operando em paralelo. A saída de um estágio serve de entrada para o seguinte.
Em um pipeline de cinco estágios, por exemplo, um estágio busca instruções, outro as decodifica, o seguinte determina os endereços dos operandos das instruções, outro busca os operandos e o última executa as instruções. (Lembram de Von Neumann?)
A seqüência de interpretação de instruções não é quebrada, mas várias instruções são processadas simultaneamente. Em um mesmo instante, uma instrução está sendo executada pelo estágio de execução, o estágio de busca de operandos procura os operandos da instrução seguinte, enquanto que o estágio de cálculo de endereços determina onde buscar os operandos de uma terceira instrução. Ao mesmo tempo, uma quarta instrução está sendo decodificada pelo estágio correspondente, enquanto que a instrução seguinte a esta é
buscada pelo estágio de busca.
Se fosse apenas isto, teríamos um pipeline perfeito. Mas...
Em instruções de desvio, o endereço da próxima instrução a ser buscada só será conhecido com certeza após a execução da instrução atual. Estudos estatísticos mostram que cerca de 30% das instruções são desvios.
Quando o pipeline processa uma instrução de desvio, o mesmo é carregado com várias instruções que podem não ser as que deveriam ser executadas após o desvio.
Esta perda de ciclos do pipeline é denominada Penalidade de Desvio. Um mecanismo de solução simples para este problema é assumir que o desvio não será realizado e buscar a instrução seguinte em PC+1.
Se a instrução for um desvio e este acontecer, é necessário restaurar a configuração original do pipeline anterior ao desvio (chama-se: fazer squashing), o que redunda em perda de desempenho.
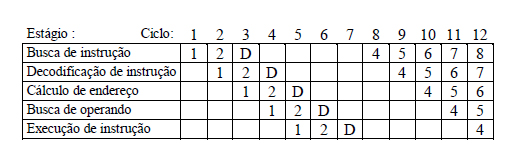
Na figura acima, D representa os desvios do programa.
Vamos montar uma fórmula para calcular mais precisamente:
Tm = Tempo médio de interpretação de uma instrução no pipeline:
Tm = (1-Pd).(1) + Pd.[Pdr.(1+D)+(1-Pdr).(1)] = (1 + D.Pd.Pdr) ciclos.
onde:
· D = penalidade de desvio, em ciclos.
· Pd = Probabilidade de que a instrução seja um desvio.
· Pdr = Probabilidade de que, sendo a instrução um desvio, este efetivamente aconteça.
· A eficiencia do pipeline é: Ef = 1/Tm = 1/(1 + D.Pd.Pdr).
Uma maneira de aumentar a eficiência do pipeline, consiste em utilizar uma predição da maneira em que o desvio será realizado, de modo a buscar a instrução que terá mais probabilidade de sucedê-lo.
Dois tipos de predições podem ser utilizadas:
· Predição estática (em tempo de compilação): compilador coloca a instrução seguinte mais provável logo após o desvio. Exemplo: desvios em loops tem grande probabilidade de ocorrer; desvios devidos a chamadas de rotinas de exceção tem pequena probabilidade de ocorrer.
· Predição dinâmica (em tempo de execução): microprograma mantém tabela de endereços de destino de instruções de desvio e informações sobre o seu comportamento.
Hora de aprofundar na memória cache!
Continua >>
A idéia do pipeline é bem simples.
imagine que você tenha de levar 4 sacas de roupa na lavanderia, lavar, secar e passar cada uma delas.
Você chega à lavanderia às 18 horas e começa o trabalho da seguinte forma:
De acordo com o desenho, vc leva 30 minutos lavando a roupa, 40 secando e 20 passando cada saco com uma certa quantidade de roupas.
Se pararmos para analizar este tempo poderia ser otimizado. Da seguinte forma:
Agora, enquanto um saco está lavando você pode secar o anterior. E como a roupa não depende de que você fique ao lado da máquina, você pode passar a leva anterior e assim otimiza o tempo.
O pipeline funciona assim. Enquanto uma instrução passa para a próxima fase, podemos otimizar o tempo pegando a próxima a ser executada.
Seria ótimo se fosse apenas isto, mas não podemos esquecer que em programas de computador temos instruções condicionais e estas podem gerar erros no pipeline, se não tratadas de maneira correta.
Vamos explicar de maneira mais técnica agora...
O Pipeline é constituído por uma seqüência de estágios operando em paralelo. A saída de um estágio serve de entrada para o seguinte.
Em um pipeline de cinco estágios, por exemplo, um estágio busca instruções, outro as decodifica, o seguinte determina os endereços dos operandos das instruções, outro busca os operandos e o última executa as instruções. (Lembram de Von Neumann?)
A seqüência de interpretação de instruções não é quebrada, mas várias instruções são processadas simultaneamente. Em um mesmo instante, uma instrução está sendo executada pelo estágio de execução, o estágio de busca de operandos procura os operandos da instrução seguinte, enquanto que o estágio de cálculo de endereços determina onde buscar os operandos de uma terceira instrução. Ao mesmo tempo, uma quarta instrução está sendo decodificada pelo estágio correspondente, enquanto que a instrução seguinte a esta é
buscada pelo estágio de busca.
Se fosse apenas isto, teríamos um pipeline perfeito. Mas...
Em instruções de desvio, o endereço da próxima instrução a ser buscada só será conhecido com certeza após a execução da instrução atual. Estudos estatísticos mostram que cerca de 30% das instruções são desvios.
Quando o pipeline processa uma instrução de desvio, o mesmo é carregado com várias instruções que podem não ser as que deveriam ser executadas após o desvio.
Esta perda de ciclos do pipeline é denominada Penalidade de Desvio. Um mecanismo de solução simples para este problema é assumir que o desvio não será realizado e buscar a instrução seguinte em PC+1.
Se a instrução for um desvio e este acontecer, é necessário restaurar a configuração original do pipeline anterior ao desvio (chama-se: fazer squashing), o que redunda em perda de desempenho.
Na figura acima, D representa os desvios do programa.
Vamos montar uma fórmula para calcular mais precisamente:
Tm = Tempo médio de interpretação de uma instrução no pipeline:
Tm = (1-Pd).(1) + Pd.[Pdr.(1+D)+(1-Pdr).(1)] = (1 + D.Pd.Pdr) ciclos.
onde:
· D = penalidade de desvio, em ciclos.
· Pd = Probabilidade de que a instrução seja um desvio.
· Pdr = Probabilidade de que, sendo a instrução um desvio, este efetivamente aconteça.
· A eficiencia do pipeline é: Ef = 1/Tm = 1/(1 + D.Pd.Pdr).
Uma maneira de aumentar a eficiência do pipeline, consiste em utilizar uma predição da maneira em que o desvio será realizado, de modo a buscar a instrução que terá mais probabilidade de sucedê-lo.
Dois tipos de predições podem ser utilizadas:
· Predição estática (em tempo de compilação): compilador coloca a instrução seguinte mais provável logo após o desvio. Exemplo: desvios em loops tem grande probabilidade de ocorrer; desvios devidos a chamadas de rotinas de exceção tem pequena probabilidade de ocorrer.
· Predição dinâmica (em tempo de execução): microprograma mantém tabela de endereços de destino de instruções de desvio e informações sobre o seu comportamento.
Continua >>